

Speech Recognition converts the spoken words/sentences into text. It is also called Speech To Text (STT).
In our first part Speech Recognition – Speech to Text in Python using Google API, Wit.AI, IBM, CMUSphinx we have seen some available services and methods to convert speech/audio to text.
In this tutorial, we will see how to convert speech that could be through Microphone or an audio file into text using some more services. Services we will be covering are from Microsoft Azure, AWS and Houndify.
Create the Virtual Environment
You can create a virtual environment by following:
Install Virtual Environment
If you don’t have virtual environment, you can install it using following command :
sudo apt install virtualenv
Create and activate Virtual Environment
You can create the virtual environment by the given command :
virtualenv env_name --python=python3
Once you have created the virtualenv, activate it using the following command :
source env_name/bin/activate
Microsoft Azure
Microsoft Azure provides Cognitive Services that has the Speech to text service.
Steps
1. Create your Azure account and login to it.
2. Before you start further, make sure to create an Azure Speech Resource using the below link. You can also create a Free Trial API Key using this link, Create an Azure Speech Resource. Once you create it, You’ll be presented with keys you can use to try the Speech service.
3. Now Install the below Package:
pip install azure-cognitiveservices-speech
Below is the code snippet for Speech to text using Azure with input of audio by Microphone:
import azure.cognitiveservices.speech as speechsdk
# Creates an instance of a speech config with specified subscription key and service region.
# Replace with your own subscription key and service region (e.g., "westus").
speech_key, service_region = "SUBSCRIPTION_KEY", "SERVICE_REGION"
speech_config=speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
# Creates a recognizer with the given settings
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
print("Say something...")
# Starts speech recognition, and returns after a single utterance is recognized. The end of a
# single utterance is determined by listening for silence at the end or until a maximum of 15
# seconds of audio is processed. The task returns the recognition text as result.
# Note: Since recognize_once() returns only a single utterance, it is suitable only for single
# shot recognition like command or query.
# For long-running multi-utterance recognition, use start_continuous_recognition() instead.
result = speech_recognizer.recognize_once()
# Checks result.
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized by Azure: {}".format(result.text))
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(result.no_match_details))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech Recognition canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(cancellation_details.error_details))
Below is the code snippet for Speech to text using Azure to transcribe audio file:
import azure.cognitiveservices.speech as speechsdk
# Creates an instance of a speech config with specified subscription key and service region.
# Replace with your own subscription key and region.
speech_key, service_region = "SUBCRIPTION_KEY", "SERVICE_REGION"
speech_config=speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
# Creates an audio configuration that points to an audio file.
# Replace with your own audio filename.
audio_filename = "your_audio_filename.wav"
audio_input = speechsdk.audio.AudioConfig(filename=audio_filename)
# Creates a recognizer with the given settings
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input)
print("Recognizing first result...")
# Starts speech recognition, and returns after a single utterance is recognized. The end of a
# single utterance is determined by listening for silence at the end or until a maximum of 15
# seconds of audio is processed. The task returns the recognition text as result.
# Note: Since recognize_once() returns only a single utterance, it is suitable only for single
# shot recognition like command or query.
# For long-running multi-utterance recognition, use start_continuous_recognition() instead.
result = speech_recognizer.recognize_once()
# Checks result.
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized by Azure: {}".format(result.text))
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(result.no_match_details))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech Recognition canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(cancellation_details.error_details))
AWS – Amazon Web Services
Amazon Transcribe is an automatic speech recognition (ASR) service that generates accurate transcripts for audio files.
Steps
1. If you don’t have the AWS account then create the account and login into it
2. Install Boto with the below command. Boto is the Amazon Web Services (AWS) SDK for Python. It enables Python developers to create, configure, and manage AWS services, such as EC2 and S3.
pip install boto3
3. Next step is to get the AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY, for that click on your account name at the top right side and select “Security credentials” from the drop-down menu.

You will find the Access keys section, “Create access key” will generate AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY

4. Once you have the Keys, now let’s create S3 bucket and upload the audio file into it.
5. Login to the AWS Console, and search for the s3 services in the search bar.
6. You will see the below like screen, click on the create bucket button, you might see a different screen if you don’t have any bucket which is created before.
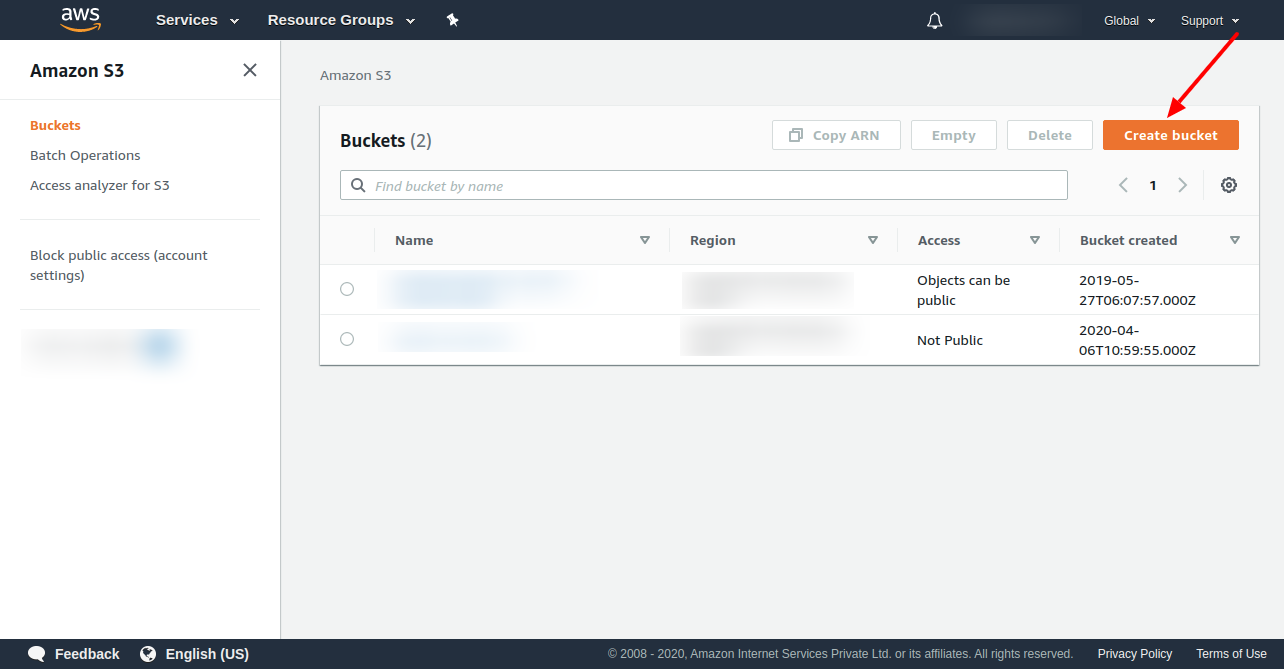
7. Now provide the bucket name and finish this step by creating the bucket.

8. Once the bucket is created, select that bucket and Upload the audio file as shown below.
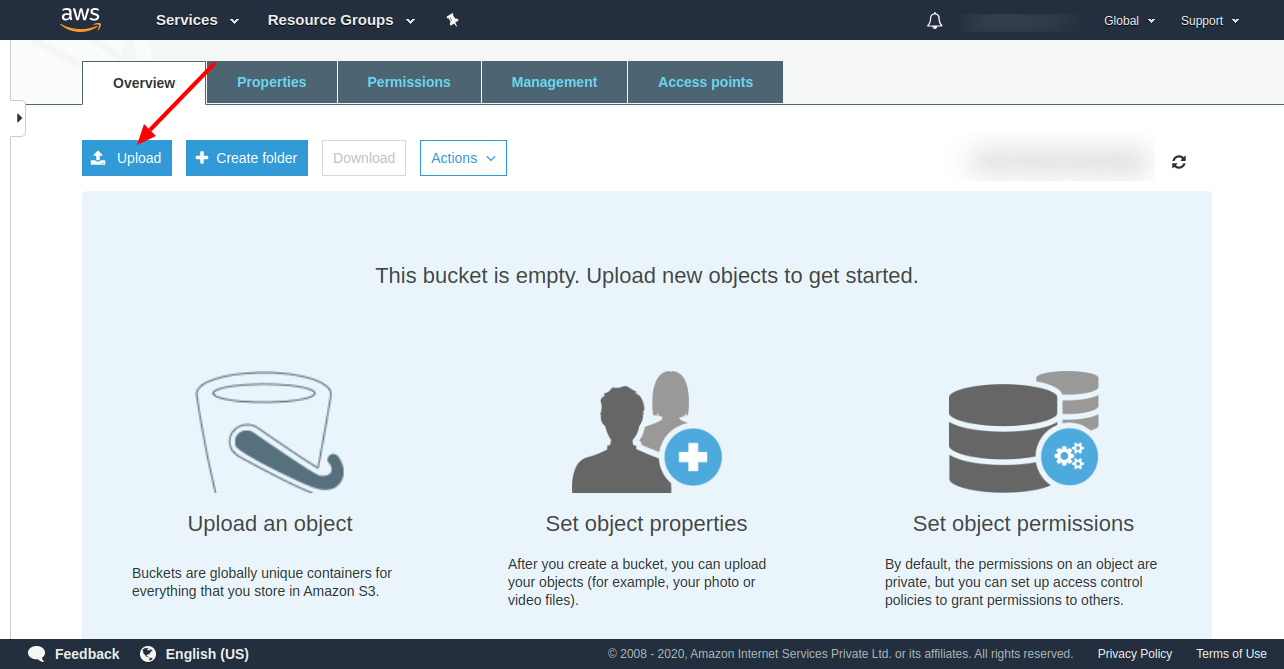
Once you have uploaded the audio file, now create a python file then copy & run the below code.
import boto3
import time
import urllib
import json
AWS_ACCESS_KEY_ID = ‘AWS_ACCESS_KEY_ID’
AWS_SECRET_ACCESS_KEY = 'AWS_SECRET_ACCESS_KEY'
job_name = 'jobName'
job_uri = 'https://S3 endpoint//FileName.wav'
# Initialize the Client
transcribe = boto3.client('transcribe', aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY, region_name='Region_Name')
# Run the Transcribe Job
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat='wav',
LanguageCode='en-US'
)
# Check the Transcribe Job Status
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(2)
print("Transcribe Job Status ==> ",status)
# Retrieve the translated text
if status['TranscriptionJob']['TranscriptionJobStatus'] == 'COMPLETED':
response = urllib.request.urlopen(status['TranscriptionJob']['Transcript']['TranscriptFileUri'])
data = json.loads(response.read())
text = data['results']['transcripts'][0]['transcript']
print("What aws service said ==> ",text)
# To Delete the Transcribe Job
response = transcribe.delete_transcription_job(
TranscriptionJobName=job_name
)
In the above code replace AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY with generated AWS keys.
job_name: A job name is required for each transcription call. It can be any string you choose, up to 100 characters.
job_uri: Path of the file you uploaded on your bucket. You can find it in your file’s properties “S3 URI”
Houndify
Houndify offers an easy way for developers to use the platform for its speech to text via its Speech to Text Only domain. Houndify has various other domain too.
Steps
1. Install the following packing:
pip install SpeechRecognition
2. Now, before installing pyaudio for your audio input/output stream, make sure you install portaudio with the following command:
sudo apt-get install portaudio19-dev
“portaudio” is a python independent C library, so it can’t be installed using pip. If you don’t have portaudio installed, you might encounter this error: ERROR: Failed building wheel for pyaudio.
3. Run below command to install pyaudio python library after “portaudio” is installed successfully.
pip install pyaudio
4. Now create the Houndify Account, Crete new client and select the Speech-To-Text Domain.
5. Once you have the Speech-To-Text Domain, now copy the client_ID and client_KEY, You can get it by selecting the Client which you have made from the Houndify dashboard under the menu Overview & API Keys.
Below is the code snippet for Speech to text using Houndify with input of audio by Microphone:
import speech_recognition as sr
# use the audio file as the audio source
r = sr.Recognizer()
#use Microphone to record live Speech
with sr.Microphone() as source:
print ('Say Something!')
audio = r.listen(source)
print ('Done!')
# recognize speech using Houndify
HOUNDIFY_CLIENT_ID = "Houndify_Client_ID" # Houndify client IDs are Base64-encoded strings
HOUNDIFY_CLIENT_KEY= "Houndify_Client_KEY" # Houndify client keys are Base64-encoded strings
try:
print("Houndify thinks you said ==> " + r.recognize_houndify(audio, client_id=HOUNDIFY_CLIENT_ID, client_key=HOUNDIFY_CLIENT_KEY))
except sr.UnknownValueError:
print("Houndify could not understand audio")
except sr.RequestError as e:
print("Could not request results from Houndify service; {0}".format(e))
Below is the code snippet for Speech to text using Houndify to transcribe audio file:
import speech_recognition as sr
# obtain path to "FileName.wav" in the same folder as this script
from os import path
AUDIO_FILE = path.join(path.dirname(path.realpath(__file__)), "FileName.wav")
# use the audio file as the audio source
r = sr.Recognizer()
with sr.AudioFile(AUDIO_FILE) as source:
audio = r.record(source) # read the entire audio file
# recognize speech using Houndify
HOUNDIFY_CLIENT_ID = "CLIENT_ID" # Houndify client IDs are Base64-encoded strings
HOUNDIFY_CLIENT_KEY= "CLIENT_KEY" # Houndify client keys are Base64-encoded strings
try:
print("Houndify thinks you said ==> " + r.recognize_houndify(audio, client_id=HOUNDIFY_CLIENT_ID, client_key=HOUNDIFY_CLIENT_KEY))
except sr.UnknownValueError:
print("Houndify could not understand audio")
except sr.RequestError as e:
print("Could not request results from Houndify service; {0}".format(e))
Using python SDK Package:
Click on the below link to download the Python Client SDK Python 3.x SDK (2.0.0)
After downloading, unzip the tarball.
You will need a Client_ID and Client_Key to use this SDK, if you don’t have client_ID and client_KEY then you can get these keys from Houndify.com by registering a new client, and enabling domains.
For providing input of audio from Microphone there is a sample program in the package named sample_stdin.py. Below are the commands to run that file.
arecord -t raw -c 1 -r 16000 -f S16_LE | ./sample_stdin.py <CLIENT ID> <CLIENT KEY>
rec -p | sox - -c 1 -r 16000 -t s16 -L - | ./sample_stdin.py <CLIENT ID> <CLIENT KEY>
For providing input of audio from Audio File there is a sample program named sample_wave.py. You will find two .wav files in the package under the folder named “test_audio”. You will get back a JSON Response based on the contents of the audio. Below is the command to run that file.
./sample_wave.py <CLIENT_ID><CLIENT_KEY> test_audio/what_is_the_weather_like_in_toronto.wav



